
Cuisine : updated & shiny

It’s been a while since my last post here, and I have updated my cuisine dashboard yesterday so here is a little follow up on what’s new in it.
First, the asynchronous handler has been updated, pushing backing data a bit differently and fixing a stupid issue on diffs. Check it out, it is needed for this new version of the cuisine dashboard.
I added a consumer that allows to use postgresql as storage backend. This does NOT replace the need for elasticsearch. It’s by making mistakes that you learn, and this one was pretty insightful : it’s better (necessary ?) to have a permanent storage you can rely on. When you come to update mappings, change stuff everywhere you don’t want to loose your data, so reindexing is the solution. There are now 3 scripts to cope with the incoming data :
- direct indexing to ES, this one does NOT remove data from message queue.
- storing to PG, data is removed from message queue
- going to both, data is removed from message queue
These scripts will probably be federated to a single one later, that will be a proper daemon (with logging, pid files and such)
UPDATE : this rewrite is done. A single script allows data consumption, indexing and storage. As a bonus, a quick and dirty packager based on FPM is provided.
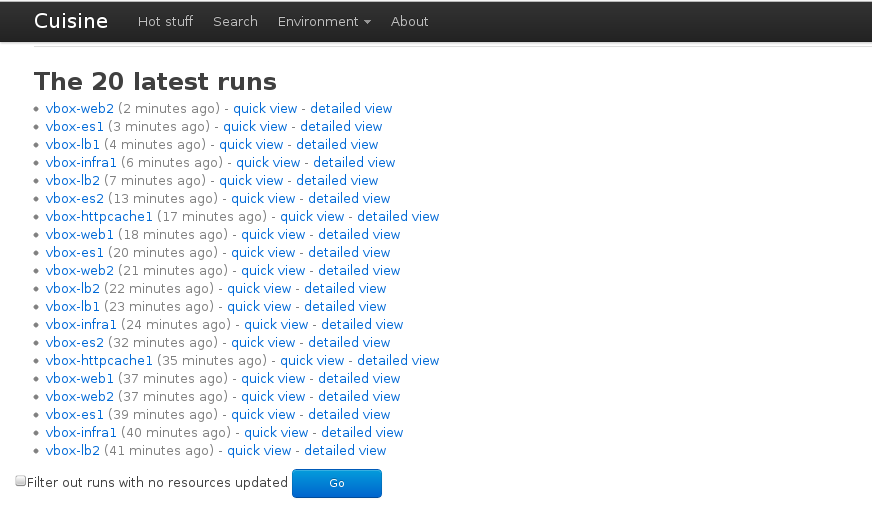
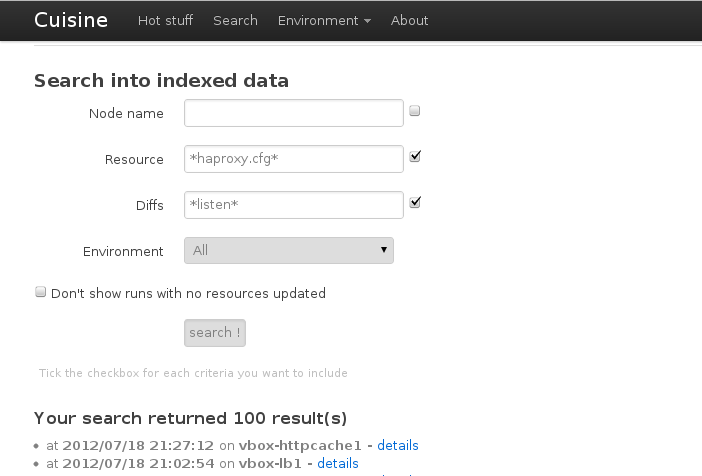
In the additions, cuisine now takes enviroments in account, you can filter when looking the last runs and in search you can restrict to a particular one.
To end this post, a few screenshots :
{kind=link}
{kind=link}